OpenAI's Q*(Q-Star) : Unveiling the Game-Changing Model
Q-learning is a fundamental concept in AI, representing a model-free reinforcement learning algorithm designed to learn the value of actions in specific states. Q-learning aims to find an optimal strategy, defining the best actions to take in each state over time to maximize cumulative rewards.
This Wednesday(11/22) marked the conclusion of the internal power struggle at OpenAI, with Sam Altman reclaiming the CEO position, but the aftermath of this event continues to reverberate among those invested in AI. The question on everyone's mind is: What led the former board of directors at OpenAI to dismiss Altman at any cost?

In a report by The Information on Thursday, it was revealed that a team led by OpenAI's Chief Scientist, Ilya Sutskever, achieved a significant technological breakthrough earlier this year. This breakthrough led to the development of a new model called Q* (pronounced Q star). The pivotal aspect of Q* is its ability to solve fundamental mathematical problems.
According to a report by Reuters, OpenAI's secret breakthrough called Q* (pronounced Q-Star) precipitated the ousting of Sam Altman.
— Rowan Cheung (@rowancheung) November 23, 2023
Ahead of Sam's firing, researchers sent the board a letter warning of a new AI discovery that could "threaten humanity". pic.twitter.com/F9bAeJG0fX
The Story Behind the Q* Model
According to Reuters, the Q* model triggered internal turmoil at OpenAI, with several employees writing to the board of directors, warning that this new breakthrough could pose a threat to humanity. This warning is believed to be one of the reasons the board chose to dismiss Sam Altman.
The ability of AI to solve basic mathematical problems may seem unremarkable at first glance, but it signifies a significant leap in the capabilities of large models. Recent research indicates that existing models struggle to generalize beyond their training data.
Engineers and researchers are increasingly engaging in discussions and speculations about Q*.
Charles Higgins, co-founder of the AI startup Tromero, told Business Insider, "Logical reasoning about abstract concepts is a fundamental challenge for large models. Mathematics involves a lot of symbolic reasoning, such as 'if X is greater than Y, and Y is greater than Z, then X is greater than Z.' Existing language models do not engage in logical reasoning; they rely on effective intuition."
So, why can the Q* model perform logical reasoning? The answer may lie in its name.
Core Features of the Q* Model
Q* implies a combination of two well-known AI approaches—Q-learning and A* search.
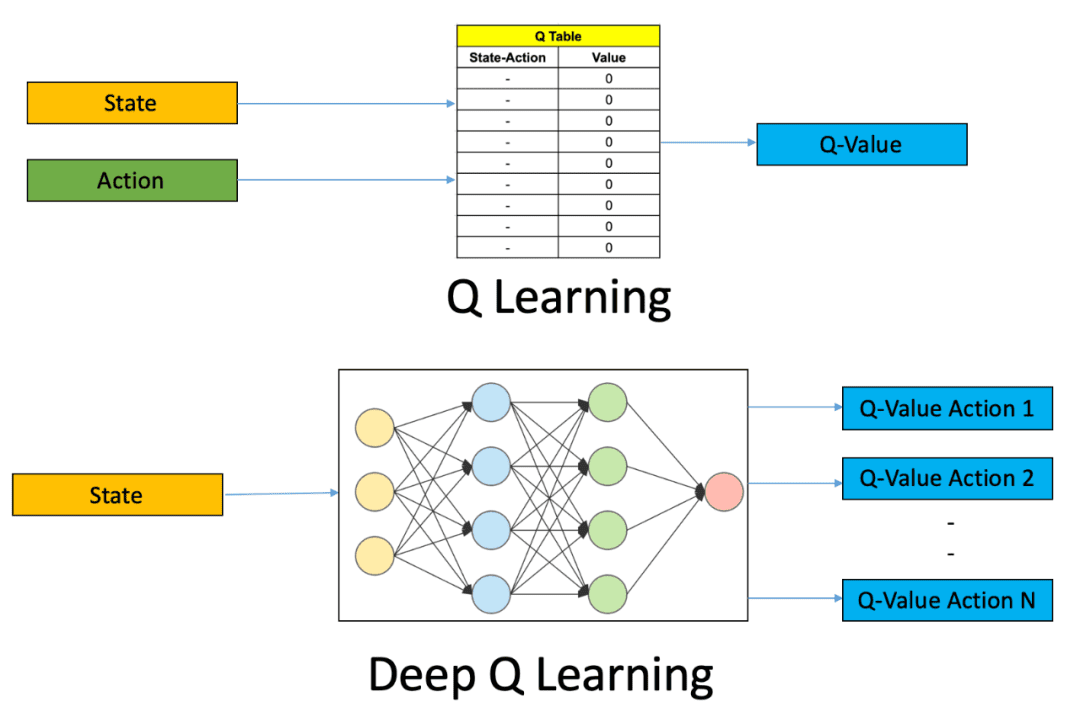
Q-learning is a fundamental concept in AI, representing a model-free reinforcement learning algorithm designed to learn the value of actions in specific states. Q-learning aims to find an optimal strategy, defining the best actions to take in each state over time to maximize cumulative rewards.
John Schulman, one of the developers of ChatGPT, introduced Q* into optimization strategies in a speech in 2016:

So, which action yields the optimal reward in each state?
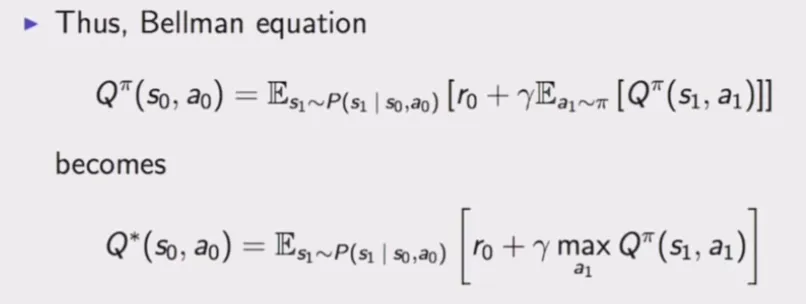
Bandit problems can be solved using the Bellman equation.
Q-learning is based on the Q function, the state-action value function. In simple scenarios, Q-learning maintains and updates a Q-table, with update rules typically represented as:

The key to Q-learning is balancing exploration (trying new things) and exploitation (using known information). In essence, Q* can implement an optimal strategy, a crucial step in algorithms like reinforcement learning for determining whether the algorithm can make optimal decisions and find the "correct solution." Typically, the term "Q Learning" does not refer to contextual search or, at least, not as a high-level name for the algorithm. It is often used to refer to the greedy behavior of an agent.
Some speculate that if Q refers to Q Learning, then * comes from A* search.
The A* (A-Star) algorithm is an efficient direct search method for finding the shortest path in a static road network, also an effective algorithm for solving many search problems. The closer the estimated distance value in the algorithm is to the actual value, the faster the final search speed.
This line of thinking is also intriguing.
In conclusion, if you want to learn more about Q-learning, you can refer to the renowned book "Reinforcement Learning: An Introduction" by the father of reinforcement learning, Richard S. Sutton.
It's worth noting that OpenAI uses the RLHF (Reinforcement Learning from Human Feedback) method for training large models, aiming to enable models to learn from human feedback rather than relying solely on predefined datasets.
Human feedback can take various forms, including corrections, rankings of different outputs, direct instructions, and more. AI models use this feedback to adjust their algorithms and improve responses. This approach is particularly useful in challenging domains without clearly defined rules or comprehensive examples. Some speculate that this is why Q* undergoes logical training and eventually adapts to simple arithmetic.
However, how much impact can the Q-learning algorithm have on achieving Artificial General Intelligence (AGI)?
Firstly, AGI refers to the ability of an AI system to understand, learn, and apply its intelligence to a variety of problems, similar to human intelligence. While Q-learning is powerful in specific domains, achieving AGI requires overcoming challenges such as scalability, generalization, adaptability, skill combination, and more.
In recent years, there have been many attempts to combine Q-learning with other deep learning methods, such as integrating Q-learning with meta-learning, enabling AI to dynamically adjust its learning strategies.
These studies have indeed improved the capabilities of AI models, but whether Q-learning can help OpenAI achieve AGI remains unknown.
Insights from Industry Experts
Aravind Srinivas, CEO of PerplexityAI, suggests that Sutton's article "The Bitter Lesson" tells us that computation is the way forward. We need more data (not just parameters) to effectively leverage computation. If we maximize the use of data on the internet, the model itself needs to generate the next token, recursively self-improving:
This should not be inherently dangerous, much like in previous computer vision research, where images were flipped and cropped to train classifiers.
Some speculate that Q* is a breakthrough similar to AlphaStar's search + LLM, an area that many AI labs are actively exploring. However, considering the limited improvements in previous attempts with GPT-4's self-verification + search, we are still far from AGI.
If the reported breakthrough of Q* indeed means that the next generation of large models can integrate deep learning techniques supporting ChatGPT with human-programmed rules, it could be a crucial milestone in technical development. This might address the challenges that current large models face, such as hallucination problems.
This could be a significant milestone in technical development. On a practical level, it is likely far from AI ending the world.
"I think the reason people believe Q* will lead to AGI is that, from what we've heard so far, it seems to bring together both sides of the brain, able to learn from experience while still being able to reason about facts," said Sophia Kalanovska, co-founder of Tromero. "This is definitely a step closer to what we consider intelligence and more likely to allow models to generate new ideas, unlike ChatGPT."
The inability to reason and create new ideas, summarizing information solely from training data, is seen as a limitation of existing large models, even for those researching in these directions—they are constrained by the framework.
Andrew Rogoyski, Head of the Human-Centered AI Research Institute at Sary College, believes that solving unprecedented problems is a key step in building AGI: "Mathematically, we know that existing AI has been proven to perform undergraduate-level mathematical operations but struggles with more advanced mathematical problems."
"However, if AI can solve new, unseen problems, not just reflect or reshape existing knowledge, that would be significant, even if the problems involved are relatively simple," he added.
Not everyone is equally excited about the potential breakthrough brought by Q*. Renowned AI scholar and NYU professor Gary Marcus expressed skepticism about the reported capabilities of Q* in an article on his personal blog.
"The board of OpenAI might indeed be concerned about new technology... Although there are claims that OpenAI has been trying to test Q*, it's not realistic for them to change the world entirely within a few months," Marcus said. "If I got five cents for every such inference (Q* might threaten humanity), I would be as rich as Musk."
Turing Award winner Yann LeCun, while discussing AI risk issues with Geoffrey Hinton, also commented on Q*:

LeCun believes, "Q* is most likely just OpenAI's attempt to replace token prediction with planning. Speculations about Q* at this point are just hot air."
Elon Musk also joined the discussion, taking the opportunity to promote his own model. He claimed that Grok, the ability you are discussing, has it:
Regarding Q*, OpenAI has yet to respond to external inquiries.
The discussion continues, and perhaps after the release of OpenAI's next large model, we will get some real answers.
Conclusion
The introduction of the Q* model has garnered widespread attention in the industry, with its performance in mathematical problem-solving and logical reasoning being particularly notable. However, for the realization of general artificial intelligence, Q* still faces a series of challenges. Amidst diverse perspectives from industry experts, we witness debates regarding the prospects and potential roles of the Q* model. OpenAI's future plans will play a crucial role in the development of artificial intelligence. As technology continues to evolve, the Q* model may become a significant milestone in the field of artificial intelligence.
References:
Learn more:
Article Link:https://zguyun.com/blog/understanding-and-prospects-of-openai-q-star/
ZGY:Share more interesting programming and AI knowledge.
Learn more: