LlamaIndex VS OpenAI API
comparing the performance of the OpenAI Assistant API and LlamaIndex in the context of RAG (Retrieval-Augmented Generation). The aim was to evaluate various RAG systems using Tonic Validate, a platform for RAG assessment and benchmarking, along with the open-source tool tvalmetrics.
We conducted a thorough analysis, comparing the performance of the OpenAI Assistant API and LlamaIndex in the context of RAG (Retrieval-Augmented Generation). The aim was to evaluate various RAG systems using Tonic Validate, a platform for RAG assessment and benchmarking, along with the open-source tool tvalmetrics. All the code and data used in this article can be found here.
In essence, LlamaIndex currently holds a significant speed advantage, especially in handling multiple documents.
Key findings include:
Multi-document processing: The performance of the Assistant API falls short when dealing with multiple documents, while LlamaIndex excels in this aspect.
Single-document processing: When documents are merged into a single document, the Assistant API shows a significant improvement in performance, slightly outperforming LlamaIndex in this scenario.
Speed comparison: "Processing five documents took only seven minutes, while OpenAI's system, under similar conditions, took almost an hour."
Stability: "Compared to OpenAI's system, LlamaIndex significantly reduces the risk of crashes."
Introduction
Last week, we tested OpenAI's Assistants API and identified some major issues in handling multiple documents. However, to better assess its performance, I will compare OpenAI's Assistants RAG with another popular open-source RAG library, LlamaIndex. Let's get started!
Testing OpenAI's Assistants RAG
In a previous article, we set up OpenAI's Assistants RAG. You can view the original setup here. Our test set included 212 articles by Paul Graham. Initially, we attempted to upload all 212 articles to the RAG system, but OpenAI's RAG restricted uploads to a maximum of 20 documents. To address this, we divided the 212 articles into five groups, creating a separate file for each group. Using these five files instead of 20, we obtained the following results with our open-source RAG benchmark library, tvalmetrics:

The results were suboptimal, with an average similarity score of 2.41 and a median of 2. This low score was due to OpenAI's RAG system failing to find relevant text in the documents, leading to unanswered queries. However, merging all 212 articles into a single document significantly improved performance:

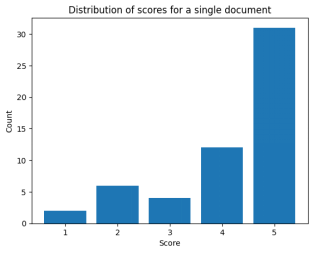
Not only did the average similarity score increase to 4.16, but the median also rose to a perfect 5.0. Response speed also improved significantly, with tests now running in minutes rather than close to an hour. This indicates that OpenAI's RAG system has strong scoring capabilities under specific working conditions, such as working on a single document. Although we achieved a high multi-document score once, it was a temporary success that we couldn't replicate.
Testing LlamaIndex
Now that we have reviewed OpenAI's results, let's evaluate LlamaIndex. To maintain fairness, we will continue using the GPT-4 Turbo Assistants API, but this time, we will disable file retrieval, forcing the Assistants API to rely on LlamaIndex. The same experimental conditions used in the OpenAI evaluation will be applied.
To import these documents, we ran the following code:

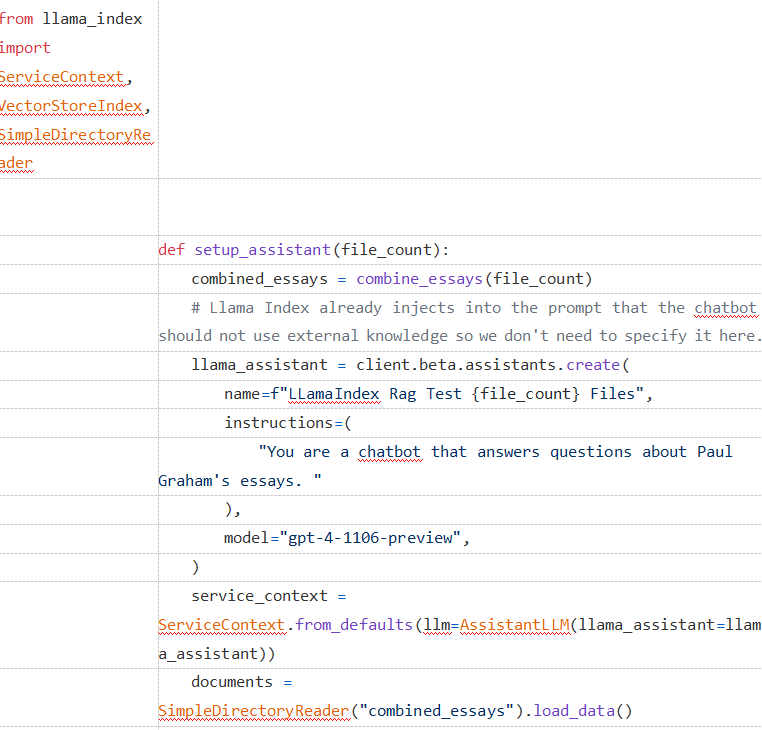
For a sampling check, let's see how LlamaIndex performs:

For both the five-document and single-document setups, LlamaIndex returned the same correct answers: Airbnb achieved its monthly financial goal of $4,000 in profit during the Y Combinator period. Unlike OpenAI's system, LlamaIndex consistently provided correct answers when using multiple documents, maintaining consistency in responses. It's worth noting that performance is comparable when using a single document. OpenAI's answers are more descriptive, but it still exhibits illusions in source counting. Therefore, I lean towards preferring LlamaIndex.
Evaluating RAG Systems
Now, let's use tvalmetrics to score LlamaIndex, an open-source library created by Tonic.ai for measuring LLM response quality. I used the following code to benchmark LlamaIndex's responses:

Using the five-document setup, I obtained the following results:
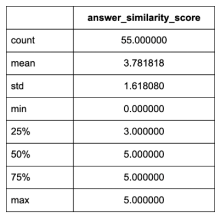
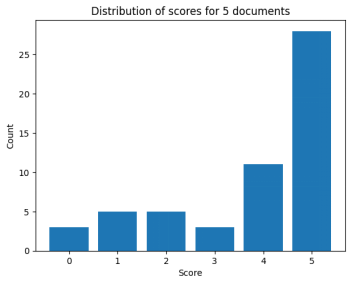
With multiple documents, LlamaIndex's performance far exceeds OpenAI's. Its average similarity score is around 3.8, slightly above average, with a median of 5.0, which is excellent. The runtime for five documents is only seven minutes, compared to OpenAI's system, which takes almost an hour with the same settings. I also observed that LlamaIndex's system is noticeably less prone to crashes compared to OpenAI's system, suggesting that OpenAI's reliability issues are more related to the RAG system itself than the Assistants API. However, for the single-document setup, LlamaIndex's performance is slightly inferior to OpenAI's RAG system, with an average similarity score of 3.7 (compared to OpenAI's 4.16) and a median of 4.0 (compared to OpenAI's 5.0).
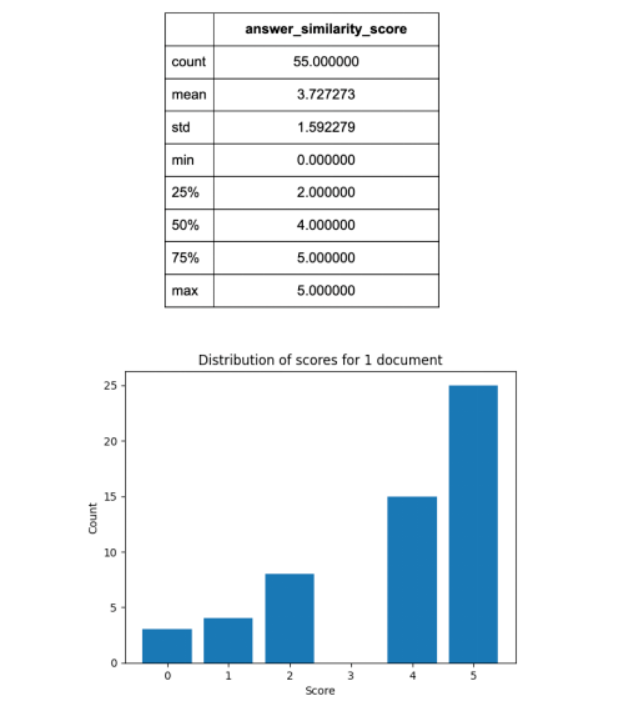
I should note that by adjusting some LlamaIndex parameters, including changing block size to 80 tokens, block overlap to 60 tokens, providing 12 blocks, and using the mixed search option in LlamaIndex, I obtained slightly better results. Doing so produced results closer to OpenAI's, but not identical:
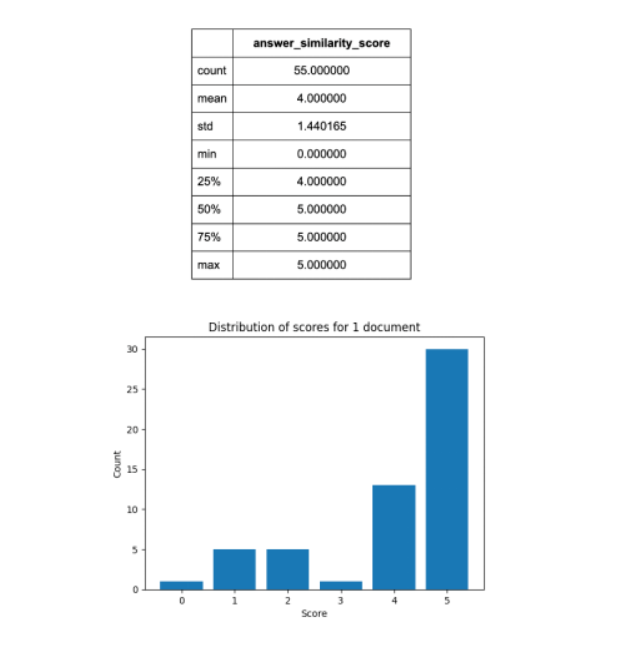
While the performance between the two systems is now closer, OpenAI still has a slight edge in the single-document scenario. Keep in mind that the settings I used were tailored to the type of questions I posed (i.e., short questions with answers very evident in the text). These settings may not be applicable in all scenarios, whereas OpenAI managed to achieve good performance under settings theoretically applicable to any situation. Although you might be sacrificing some performance due to the limited customization allowed by OpenAI, it ultimately depends on whether you prefer better results by gaining more customization in certain scenarios or opting for a versatile out-of-the-box tool that performs well in specific situations (limited to single documents only).
Conclusion
OpenAI's RAG system appears promising, but performance issues in handling multiple documents significantly diminish its practicality. While their system performs well on a single document, most users would likely want to run their RAG system on a variety of different documents. Although they could cram all documents into a single, massive file, that's just a workaround and shouldn't be what a high-performing, user-friendly RAG system requires. Coupled with the 20-file limit, I'm hesitant to recommend anyone to immediately replace their existing RAG pipeline with OpenAI's RAG.
However, as mentioned earlier, OpenAI still has the potential for improvement. While conducting some sampling checks on their GPT-based RAG system, I noticed significantly better performance in handling multiple documents. The poor performance is limited to the Assistants API itself. If OpenAI works to elevate the quality of the Assistants API to the level of GPT and eliminates the file restrictions, I can envision companies considering a move to OpenAI's RAG, provided they are willing to forgo some of the customization offered by LlamaIndex. However, until that day comes, I recommend continuing to use LlamaIndex. All the code and data used in this article can be found here.
Learn more:
Article Link:https://zguyun.com/blog/llamaindex-vs-openai-api/
ZGY:Share more interesting programming and AI knowledge.
Learn more: